



Vowels
For vowels, a different set of terms is used.Transcribing English
Phonology
Phonemes
Syllables
Sonority
Allophones
- high-mid-low: height of the tongue in the mouth
- front-central-back: frontness or backness of the tongue in the mouth
- rounded-unrounded: the state of the lips in English, as in many languages this is predictable: rounded for high back and mid back vowels, unrounded for other vowels.
- tense-lax : roughly, the degree of tension in the tongue
- Just a velar nasal [ŋ]
- singer, hangar
- Here "ng" is a digraph, like "ch"
- A velar nasal [ŋ] followed by [g]
- finger, anger
- Here the two letters represent two sounds, like "nk" in thinker
- Voiceless fricative [θ] in thing, ether, thigh
- Voiced fricative [ð] in this, either, thy
- sound [i] spelling fee, tea, be, key, thief, Leigh
- sound [e] spelling say, great, made, prey, Mae
- sound [u] spelling do, food, new, sue, soup, rude
- diphthong [ay] spelling sigh, I, eye, my, hide, lie
- sequence of sounds [si] beginning of word: see, sea, senile, seize, scenic, siege, ceiling, cedar, cease end of word: juicy, glossy, sexy
- actual words with obstruent + liquid (two steps) brick, true, free, crab; play, blue, flea, glib
- possible words with obstruent + liquid blick, clee
- impossible words with obstruent + nasal (just one step) *bnick, *fnee, *gmue, *dmay
- historical loss of initial consonant in obstruent + nasal (letter now silent) knee, knight, gnat, gnaw
- top~stop, take~stake, tie~sty, etc.
- kin~skin, cope~scope, can~scan, etc.
- it's learned unconsciously by children imitating (quite accurately!) the details of the language around them
- it's systematic, applying to all words with voiceless stops, not just some random selection
- it's defined in terms of a natural class (here "voiceless stops") rather than some arbitrary set of three consonants
The terms refer, loosely speaking, to the location of the main tongue constriction within the mouth.
| Front | Central | Back | ||
| High | Tense | i | u | |
| Lax | I | U | ||
| Mid | Tense | E | ə | o |
| Lax | ε, | Λ | ɔː |
Most of these symbols are relatively standard, at least to the degree permitted by web-friendly characters; as often in these circumstances, the ə is used for schwa, an upside-down "e" letter.
Here are English words containing the vowel sounds referred to by each of these symbols. These words also exemplify the consonant symbols.
| i | see | [si] |
| seat | [divə] | |
| diva | [pIn] | |
| e | say | [se] |
| plain | [plen] | |
| take | [tek] | |
| ε, | [tek] | [lεt] |
| ten | [tεn] | |
| æ | hat | [haet] |
| plaid | [plaed] | |
| laught | [laef] | |
| a | hot | [hat] |
| papa | [papə] | |
| ɔː | saw | [sɔː |
| caught | [kɔː] | |
| o | sew | [so] |
| roam | [rom] | |
| home | [hom] | |
| u | put | [put] |
| took | [tuk] | |
| u | ooze | [uz] |
| use | [yuz] | |
| bloom | [blumn] | |
| home | [hom] | |
| fume | [fyum] |
Λ,while slightly lower, is extremely similar to ə. is the stressed vowel in "cup", while ə is the unstressed (second) vowel in "papa".
| Λ ə | up | [Λp] |
| sofa | [sofə] | |
| attack | [ətaek] |
In addition to these simple vowels, English has several diphthongs (i.e. vowel sounds that essentially combine a vowel with a glide or semi-vowel in a single unit). These are written, therefore, with two phonetic symbols, even if they can (in the case of "long i") be written with one symbol in English spelling.
| ay | tie | [tay] |
| sigh | [say] | |
| my | [may] | |
| mine | [mayn] | |
| aw | cow | [kaw] |
| bough | [baw] | |
| cloud | [klawd] | |
| oy | boy | [boy] |
| coin | [koyn] |
(It should be noted here that, in most dialects of English, all of the tense vowels are actually diphthongs. For example, say, which we have represented above as [se] is actually pronounced [sey] by most speakers.)
Transcribing English
There are lots of things to be careful about when doing phonetic transcription. Most important is to pay attention to the sounds, and don't be distracted by the spelling. English spelling is not designed to faithfully represent the sounds of words and is frequently quite misleading in this respect, so it's best to try to ignore it. For example, a single letter (or combination of letters) "ng" in English spelling can represent two different pronunciations.
These have to be distinguished in a correct transcription, even though the spellings are the same -- that's a defect of English orthography.
"finger" = [fIŋgr]"singer" = [sIŋr]
"think" = [θIŋk]
(cf. thin, thing as first part of this word)
Similarly, "th" is ambiguous.
And vowels especially are spelled chaotically -- but in phonetic transcription a particular vowel sound is always written the same way. Some examples:
Phonology: the structure of sound
Recall the basic distinction mentioned earlier.
phonetics: the physical manifestation of language in sound waves; how these sounds are articulated and perceivedphonology: the mental representation of sounds as part of a symbolic cognitive system; how abstract sound categories are manipulated in the processing of language
Thus phonetics refers to the physiological and acoustic parts of the following diagram, while phonology resides in the brain.
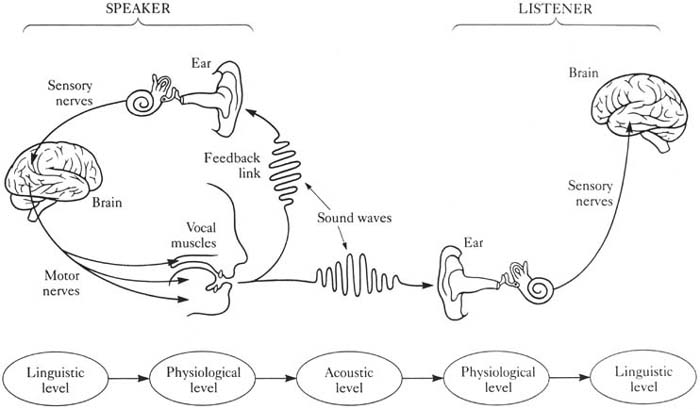
From The Speech Chain
Phonemes
The phonological elements of a language are the basic, distinctive sounds, also called phonemes. In English, these are the following (for a dialect of Standard American English).
consonants: p, t, k, b, d, g, č, , f, θ, s, š, h, v, ð, z, ž, m, n, ŋ, l, r, w, y
vowels: i, u, I, U, e, o, , ə, :, æ, a, ay, aw, oy
These sounds are said to be "distinctive" because they can be used to make contrasts between different words. This can be illustrated for the stops, using minimal pairs (words that differ in exactly one sound).
pill
till
kill
bill
dill
gill
And for the vowels (We can't get an exact minimal set for the entire range of vowels in the context [h_d], so in some cases the initial consonant also differs. For each individual pair of vowels, however, we could come up with a minimal pair.):
heed
who'd
hid
hood
aid
ode
head
HUD
awed
had
odd
hide
how'd
Boyd
And for the nasals:
rum
run
rung
In English, the velar nasal [h] can't occur at the beginning of a word -- cf. map, nap, *ngap -- which will lead us to the next issue, the way these elements are organized into words.
But first, note that a basic way in which languages differ is their inventory of sounds, or phonemes. For example:
German has the voiceless velar fricative [x], as in Bach "creek". English has voiceless fricatives such as [s] and velars such as [k], but it doesn't have a single phoneme that has both of these properties. German also has the high front rounded vowel [ü], as in kühn "clever". Again, English has high front [i] and rounded [u], but these properies are not combined in one vowel. English [θ] sets it apart from many languages, including German and French. They have several voiceless fricatives, but not the interdental. When you learn a new language, one of the things you have to do is learn the "list" or inventory of sounds. That's what children have to do also, when learning their native language.
Syllables
The phonological structure of a language -- the way these elements are organized -- includes the notion of syllable and its subparts. This structure is crucially involved in describing the possible words of a language.the onset or consonant(s) at the beginning of the syllable English normally permits up to two consonants but in addition, [s] can be added to the beginning of many syllables as well, making up to three consonants all sounds can occur in this position except for [ŋ]
the nucleus or vowel that is the core of the syllable sometimes a consonant can serve as the nucleus, as in the second syllable of kitten.
the coda or consonant(s) at the end of the syllable English normally permits up to two consonants at the end (belt, jump, arc) but in addition, certain sounds such as [s, t, θ] can be piled up (belts, sixths)
Here's a general schema of how syllables are constructed.
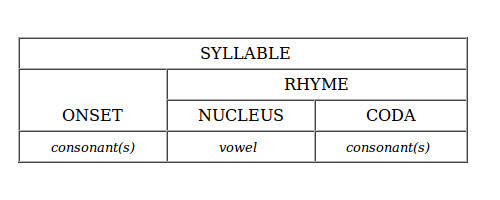
The category rhyme simply brings together the nucleus and the coda, so the rhyme part of the syllable blend is the nucleus [E] and the coda [nd]. The reason for this name should be obvious: in order for syllables to rhyme, what has to match is just this part of the syllable -- trend, end, spend, etc. (In longer words, rhyme is defined as matching this part of the stressed syllable and all the way to the end of the word: flower, power, shower, tower, hour, scour, etc.)
Sonority
Human speech, like many animal vocalizations, tends to involve repetitive cycles of opening and closing the vocal tract. In human speech, we call these cycles syllables.A syllable typically begins with the vocal tract in a relatively closed position -- the syllable onset -- and procedes through a relatively open nucleus, then closing again while approaching the coda or the next syllable's onset. The degree of vocal tract openness correlates with the loudness of the sound that can be made.
Speech sounds differ on a scale of sonority, with vowels at one end (the most sonorous end) and obstruents (stops, affricates, fricatives) at the other end. In between are the liquids [l] and [r], and nasal consonants like [m] and [n].
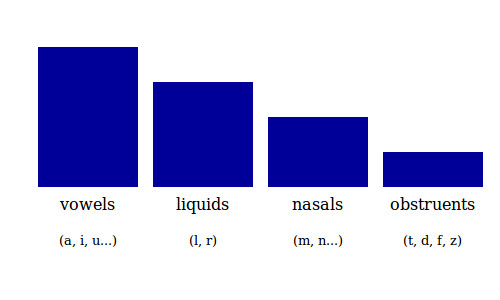
Languages tend to arrange their syllables so that the least sonorous sounds are restricted to the margins of the syllable -- the onset in the simplest case -- and the most sonorous sounds occur in the center of the syllable -- most often a vowel. Here are some typical English syllables that illustrate this pattern.
"soon"
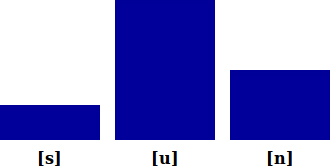
And in "pretending" each syllable corresponds to a peak in sonority.
"blend"
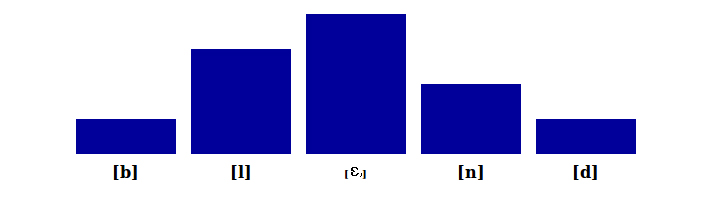
And in "pretending" each syllable corresponds to a peak in sonority.
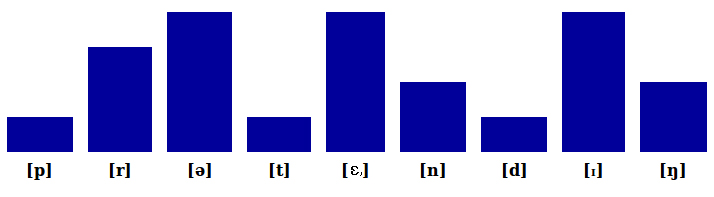
As a consequence of this sonority requirement, an English word such as film is one syllable:

But if we try to reverse the last two consonants, the hypothetical word fiml comes out as two syllables, since [l] is a new peak, higher in sonority than the preceding nasal. (This new word would end just like pummel.)
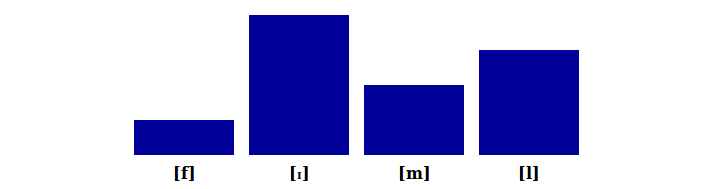
Similarly, if we change the [l] in film to an obstruent such as [z] in hypothetical fizm, once again we end up with a new syllable. (It would rhyme with prism.)
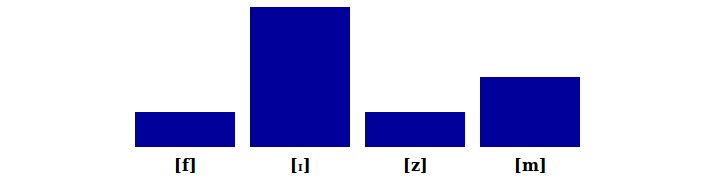
These syllabifications aren't something we need to learn for each word: they're a general property of the language. That's why we know how these hypothetical words would be pronounced.
In these last two words, the consonant serves as the sonority peak at the end of the word. The consonant is syllabic, serving as the nucleus in the absence of a vowel. English permits nasals and liquids to serve in this way, at least in unstressed syllables.
prism, bottom, sump'm (for "something"), cap'm (for "captain")
hidden, button, kitten, risen
bottle, little, towel
swimmer, higher, butter
For [r], the consonant can function as a vowel even in a stressed syllable.
bird, fur, word
In some dialects, such as Standard British, Boston, and Coastal Southern US, any [r] in the rhyme of a syllable (whether nucleus or coda) loses its r-ness and becomes a schwa-like vowel. These are called "r-less" dialects.
Another general property of English is that there are restrictions on what consonants can serve as an onset cluster -- i.e. the string of (two) consonants at the beginning of a syllable. It's not enough for the sonority to increase from the first consonant to the second: it has to increase by two steps.
This too is part of our general knowledge of the language: we can distinguish blick and *bnick as "possible" and "impossible" even if we've never heard either word before.
But what about words like snow, with an obstruent + nasal onset cluster? You can take any ordinary English onset, and (subject to some restrictions) tack an [s] on the front of it, completely ignoring sonority. This includes clusters of two consonants that obey the general rule; if the first of these is a voiceless stop, [s] can be added to make three consonants.
snow (cf.no)
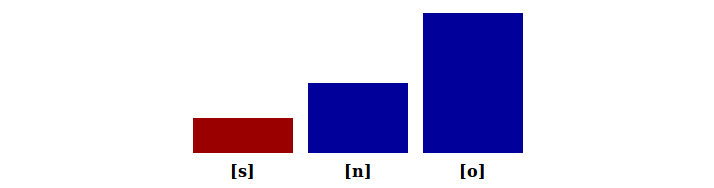
stop (cf.top)
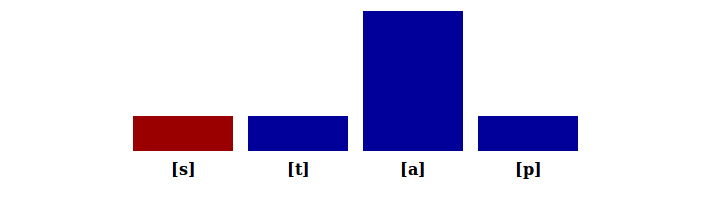
spray (cf.spray)

This is a special property of [s] and no other obstruent in English. Essentially, it's because [s] is a perceptually salient sound with loud fricative noise: it doesn't depend in the normal way on syllable structure. Many other languages give similar special treatment to [s] and related sounds; in German (and Yiddish), for example, it's the (alveo)palatal fricative, as in Schmutz "dirt."
Once again, syllable structure is a way in which languages differ.
Hawaiian, for example doesn't allow any coda consonants at all, and a maximum of one consonant in the onset. This means that borrowed words get a lot of extra vowels, to create new syllables of the proper type.
ink > 'înika
Norman > Nolemana
Polish, on the other hand, allows more consonants at the beginning or end of a word than English does. This is why some Polish names are hard for English speakers to pronounce, such as Gdansk or Zbigniew Brzezinski.
bzdura "nonsense"
babsk "witch"
grzbiet [gzhbyet] "back"
marnotrawstw [-fstf] "of wastes"
A language learner, when exposed to lots of examples of words and syllables in a new language, comes to understand what structures are possible in that language by observing the attested patterns.
Allophones
There are often differences in the way a phoneme is pronounced in a specific context. The variant pronunciations are called allophones ("other sounds").When it's important to make this difference:
we'll use [square brackets] to indicate sounds from a phonetic point of view, i.e. focusing on their physical properties and the details of actual pronunciation; and we'll use /slashes/ to indicate sounds from a phonological point of view, i.e. as part of an abstract representation independent of potential differences in the way the sound in pronounced in specific contexts. In other words, in the ideal case, [ ] = allophone, / / = phoneme.
A classic example of sound alternation in English, which I mentioned in the first lecture, relates to the [s] found at the beginning of a syllable before a voiceless stop.
Although a word like spin is basically pin with [s] added, the /p/ in each case is pronounced differently.
pin contains an aspirated version of /p/, with a puff of air after the stop is released; this is written [ph]
spin contains a plain /p/, without a puff of air after the stop; this is written just [p]
The same is true for pairs like pit~spit, pot~spot, pair~spare, etc. A simple statement of this alternation is as follows:
| the phoneme /p/ becomes: | allophone [p] | immediately following [s] |
| allophone [ph] | at the beginning of the word |
But the same generalization holds not just for /p/ but for the other voiceless stops, /t/ and /k/. Compare these word pairs:
So more accurately, there's a single general statement that covers all these cases, stated in terms of natural classes.
| voiceless stops are: | unaspirated | immediately following [s] |
| aspirated | at the beginning of the word |
The aspirated and unaspirated versions of the voiceless stops are in complementary distribution : each occurs in its own context, which does not overlap with the contexts of the other. The rule stated here assumes words of one syllable only. The full statement of where aspiration occurs in English is more complex: voiceless stops are aspirated when they occur syllable-initially and are followed by a stressed vowel (rápid, raphídity); as well as word-initially regardless of stress (photháto). At the beginning of a word, a preceding /s/ prevents the stop from being syllable- or word-initial. If related words (containing the same morpheme, or meaningful element) have different stresses, then we often find alternations in whether the same underlying sound /t/ is pronounced phonetically as plain [t] etc. or aspirated [th] etc.
| rápid [p] | rapídity [ph] |
| authéntic [t] | authentícity [th] |
| récord [k] | recórd [kh] |
This process is completely unconscious for most speakers, and often quite hard to unlearn. English speakers who learn a language like French or Spanish, in which all voiceless stops are unaspirated, typically impose aspiration according to their native rule; but that's wrong for these languages, and sounds foreign. Similarly, a French or Spanish speaker learning English will typically fail to produce aspiration in the right places; this is part of what it means to have a foreign accent. Aspiration in English is a small example of what phonological knowledge consists of:
The study of phonology is largely the investigation of alternations like this -- what changes occur, what sounds undergo them, and in what contexts.